Interview with James Stine - Open Source Standard Cells
In this interview with Professor James Stine, we talk about:
- Why is Open Source the key to innovation?
- What do students struggle with most when learning to design standard cell libraries?
- What are the biggest misconceptions engineers have about standard cells?
- What’s James’ tool flow?
- How many cells are needed to make a library?
- Why do we need another library for Global Foundries (GF) 180?
- How far are open source tools from commercial tools?
- Could automated layout of standard cells compete with hand layouts in nanometer processes?
- With Moore’s Law slowing down, do any circuit families deserve a second chance?
- Why would nVidia make a 7.5T standard cell library?
Text of the interview is included below.
Resources
- Follow James on Twitter: @JamesStineJr
- What is a Standard Cell?
- How is HDL synthesized?
Q & A
When teaching the design of standard cell libraries, what do students struggle with most?
For students, I think the hardest part is understanding that standard-cells are meant to be utilized with Electronic Design Automation (EDA) tools, so their layout is slightly different than traditional layouts. Layouts are carefully planned layers that form transistors. But they can have different objectives or combinations of them (Power, Performance and Area (PPA)). Standard-cell layouts are designed to fit together to form a System on Chip design. Therefore, pins must be aligned to grids or have good access to them, be able to be placed on top of each other, as well as connected via EDA tools. Once I explain to students how they are different from traditional layout, they get the idea well.
Another challenge is getting students to understand characterization. Characterization is important in that it simulates a cell thousands of times to get accurate information that goes into information that SoC tools use. Traditional standard-cells typically use multiple transition delays (i.e., time that the signals rise and fall) as well as the load they go into to form an idea how to connect to it. Using the wrong load or transition delay (or not enough of these values) can lead to a poor cell library.
What are the most important parts of standard cells that engineers understand least?
I think engineers at least understand that standard-cell libraries are not always correct. Good standard-cell libraries have good characterization as well as multiple corners. Standard-cell libraries have layouts that they use to base the library off. However, if a user forgets to account for parasitic effects or uses a bad load, it can lead to a library that cannot perform the best it can when implemented. Even commercial libraries can make mistakes with certain elements that cause issues related to their use. For example, they may not employ good boundaries that cause certain layout (gds) errors when put together. This is why standard-cell libraries require good testing after they are created. I have never created a standard-cell library that works the first time – it usually involves multiple attempts to get it right.
What is your (James Stine) tool flow?
I love open-source tools. We typically use magic to create layouts first based off good schematics for a given PDK. The schematics are created in xschem and then used as a basis for producing each cell. Cells usually but not always have the same height, but the pitch that each cell uses will be based on how the pins are spaced. This is why good testing of the layout is needed with magic to figure out a specific height, usually measured in tracks. Commercial standard-cell libraries tend to have small track sizes to squeeze as much as space out of a design. However, smaller tracks come at the expense of tighter layout constraints and may make layouts grow horizontally.
We love magic as a layout tool as its super easy to use, compiles for multiple programs, helps students learn the PDK fast and efficiently, and can be used to produce reliable commercial-quality layout. We use magic to measure the track height carefully and then produce a handful of cells. We then use these cells with a characterization tool that runs SPICE thousands of times to produce information that EDA tools can use (e.g., Liberty files). We also use magic to produce Layout Exchange Formats (LEFs) that are commonly used among place and route tools to minimize the information needed to stitch all the layout together. Minimal is not a good word here as it’s the minimal information needed to help the layouts work – this is usually called cuts and routes, where cuts are contacts/vias and routes are wiring that is used for routing.
Oklahoma State University is working on a characterization tool that is open source, but for right now, we employ Liberate from Cadence Design Systems as we have used for the last 20 years reliably and efficiently. However, our goal is to eventually support a complete open-source tool flow with standard-cell creation.
What future challenges are you looking to tackle?
The future challenges are many in this area. All are welcome to participate in this vibrant area, but I think one of the major challenges is getting more people interested in this wonderful area. I know I am very grateful for people like Matt Venn and others who go out of their way to help others learn this material and show them that they can participate and do well in it. These jobs are not easy as it is not an easy area to learn or navigate in and people like Matt do amazing jobs to help others.
I think another challenge is creating libraries that help support objectives in this vibrant area. For example, modern standard cell libraries have specialized cells to help low-power and power conversion for the rapidly growing area of embedded and low-power environments. These cells are not like traditional cells like a NAND or NOR gate and may require help from users to characterize them correctly. This challenge translates to getting characterization to pull out the correct information for that cell and many characterization tools are not straightforward with how this is done yet, in my opinion.
Will automated layout of standard cells will be competitive with hand layout in nanometer processes?
Carefully crafted and designed hand layout almost always beats automated standard-cells. Therefore, places like AMD and Intel spend lots of time making layouts that target their objectives.I do think in certain instances, especially with the new breed of EDA tools that employ machine learning (ML), might come close or even surpass what you could do with layout. I think this is a great question that deserves more exploration. On the other hand, computer architectures that want to get every shred of performance out of a layout will typically always use hand layout to optimize a design. I personally feel that EDA tools may help enhance that with some automation now and into the future though.
I did some experimentation with automatic layout generation with a tool called Cadabra for the FreePDK that was funded by the Semiconductor Research Corporation. It worked well and my thought is that they still work well. However, they may be difficult for smaller feature sizes. Consequently, there needs to be more work in this area. This automatic library can be downloaded at http://freepdk.ecen.okstate.edu for anyone who is interested in trying something similar.
I know Matt has a colleague who has worked in this area and their work may be good to explore, as well. That is, automatic layout of standard-cells is important for future work. I also believe that Machine Learning techniques may also enhance this area as it is currently done with some of the work with the great work from OpenROAD. The OpenROAD innovators including Andrew Kahng (at UCSD) and Tom Spyrou have made tremendous contributions for open-source tools using place and route. And I also believe their work may help automatic layout of standard-cell libraries, as well. Unfortunately, I do think that there needs to be more research into this area.
Are there any circuit families from the past (dynamic logic, pass transistor logic, domino, multi-output, etc.) that deserve new attention with Moore’s Law slowing down?
This is a fantastic question. I do think that these circuit families are important and will help improve current designs especially as Moore’s Law is slowing. These logic families are just as important today as they were back in the 90s when they were long thought as the panacea for performance boosters. I always tell students the next breakthrough in science may be something that was thought of in the early part of the 20th century might be the next innovation that spurs the next improvement in technology. Students need to know about what history exists to improve the next innovation. Ignoring these facts could lead to companies not innovating which is usually a sign of death for these companies that once dominated the landscape.
Can you share any details on the open-source version of liberate?
Sure, we are working on an open-source version of liberate that will utilize python to create a competitive open-source version of liberate. We have a version that we are working on and that we hope to get into the public in the next 2-3 months that will create good ways of characterizing libraries for both power and speed. Right now, our program is a little buggy and still needs some hand holding before it can be released. But, as stated previously, we are committed to providing a characterization tool that can be used by anyone who wants to characterize libraries.
I am inspired by others such as Tim Edwards who made so many wonderful innovations with magic as an open-source layout tool. His invaluable contribution cannot be underestimated as his tool really has transformed magic from what I used in the 1980s. It is truly an almost commercial grade version of a layout edit but completely open source. Moreover, Tim’s ability to help others is also something of a marvel – he typically has spent loads of his free time helping others learn how to make layout better. This inspires me to create a tool that tries to do the same for characterization.
How many cells are enough cells? You can cover all functions with a FF and NAND but things improve by adding more logic functions, often increasing in complexity and drive strengths.
Newer commercial synthesis programs utilize innovations in compiler technology and grammar understanding of compilers to make High-Level Synthesis (or HLS) a reality. Some commercial synthesis programs have a set number of cells that they need in a library to help HLS work well. How much is needed beyond these minimal numbers of cells to improve standard-cell libraries is another great research question. I hope again that this can be explored more. And I firmly believe this is why my libraries are important to this field and why I try to give all my scripts, tools, and everything I used to create these libraries in my repositories. I believe that others should benefit from our experience. Other people have helped me, and I try to return the favor for the immeasurable gift that these other researchers have given me.
But what’s the marginal improvement of adding the 10th vs 100th cell? How do you decide the optimum number of cells to design?
This is a great question, and I am not sure the answer to this as I alluded to earlier. I think this is something that needs more exploration as I alluded to previously.
How far are we in terms of opensource tools from commercial tools? How far away from now would we see competitive opensource tooling in the field?
Ooh..another fantastic question. I think open source is the key to the future in this area. But I also feel commercial tools help others tools and that open-source tools help commercial tools and vice versa. I believe firmly that both are needed and that they need to exist together in the same stratosphere to be effective. I do not think that open-source tools will ever be within 1% of commercial tools, but I do feel that with more open-source options that they may outperform tools that are commercial. You see that with my great Ph.D. student Teo Ene’s prefix adder tool that he made open source. Some designs he produced in this design outperform commercial synthesis results. So, I think that in the next 5-10 years you will see more of this. I do predict that you will see many more enhancements possibly enhancing commercial tools via open-source software. I only hope that more commercial tools embrace open-source tools as I do believe they are the path to the future.
Any theories on why nVidia would make a 7.5T standard cell library?
I am not familiar with the NVIDIA 7.5T std cell library. As I mentioned previously small track sizes are used to squeeze as much out of a gate as possible but keep things small. Having done 9T cells for GF180, I know that the smaller you get, the more time is needed to make sure all connections get connected correctly. As you shrink the number of tracks, you typically must use more metals to avoid DRCs. This can cause issues as you use in SoC designs as upper-level metals are the bread and butter to connecting your entire design together. If you use more metals, this means there is less room at the top for connecting designs which can cause issues.
Another fantastic question on the number of cells needed for a library. There has been some study, but I do not think there is enough research on this area in the public domain. I suspect commercial libraries know answers on this area more but are less likely to publicize it to avoid giving too much information to their rivals. So, I think this is a good area for some research and I always hope that either I or my libraries can help explore this process more.
Screenshots of the GF180mcu cells that are currently available opensource
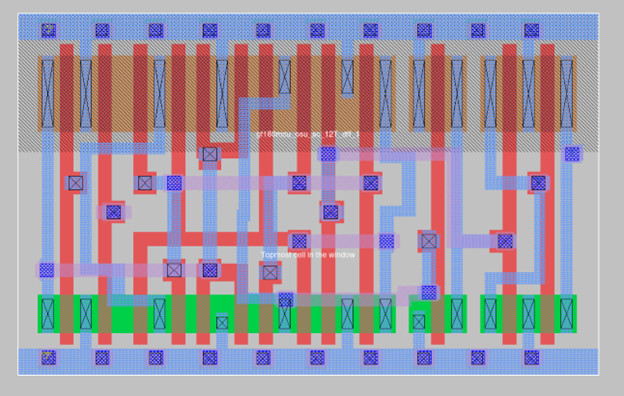 12T DFF Cell from GF180mcu OSU Library
12T DFF Cell from GF180mcu OSU Library
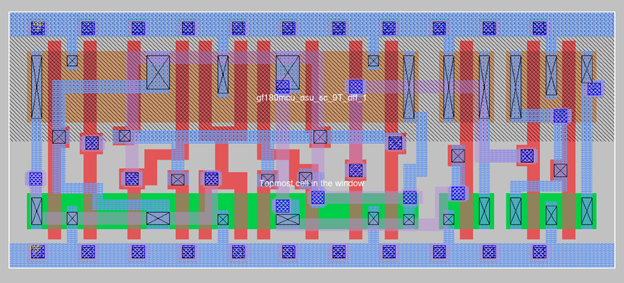 9T DFF Cell from GF180mcu OSU Library
9T DFF Cell from GF180mcu OSU Library
 Sample Place and Route using 12T GF180mcu OSU Library
Sample Place and Route using 12T GF180mcu OSU Library
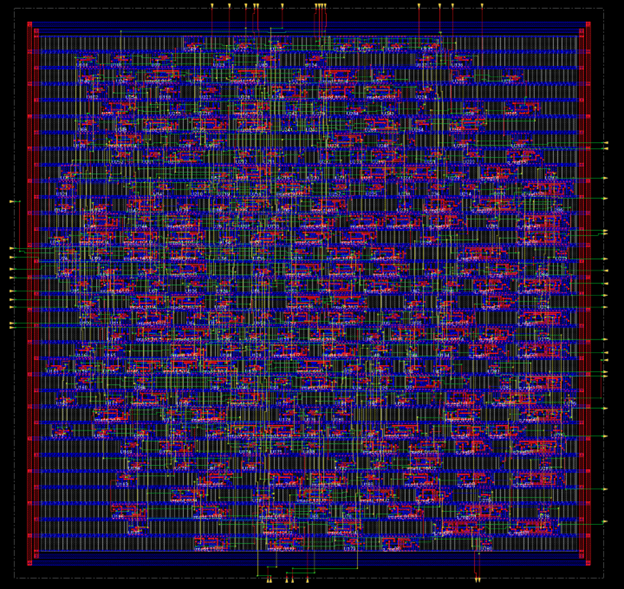 Sample Place and Route using 12T GF180mcu OSU Library
Sample Place and Route using 12T GF180mcu OSU Library
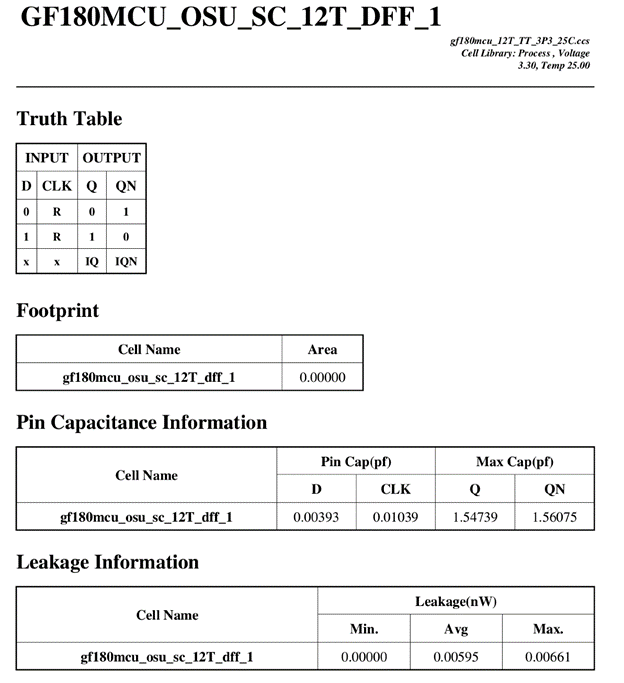 Sample Output from Characterizer for 12T GF180mcu OSU Library
Sample Output from Characterizer for 12T GF180mcu OSU Library
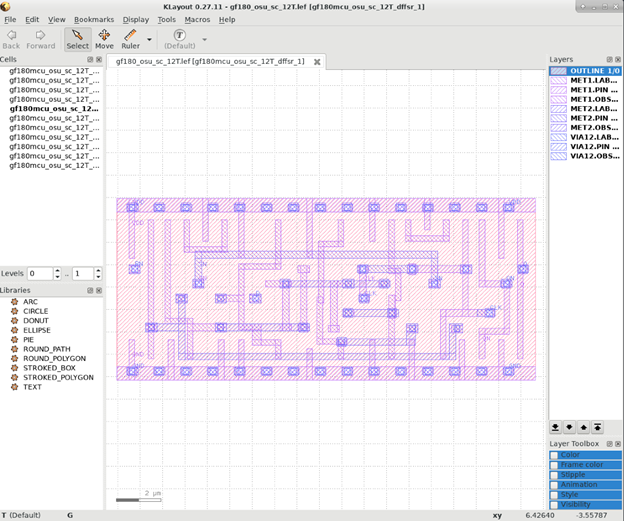 Sample library exchange file (LEF) Output from Characterizer for 12T GF180mcu OSU Library
Sample library exchange file (LEF) Output from Characterizer for 12T GF180mcu OSU Library